För att utföra statistiska analyser behöver man inte bara känna till några statistiska metoder. Man behöver också kunna hantera, filtrera, sortera och på olika sätt vrida och vända på data. Samtidigt behöver man programvara där de senaste metoderna finns tillgängliga. Sedan många år tillbaka är det bästa valet av statistisk programvara R, som även är det verktyg som jag själv använder sedan 13 år.
Min nya bok Modern Statistics with R handlar om hur man kan använda R för att hantera, visualisera och analysera data. Explorativa metoder, klassisk statistik och maskininlärning finns med. Utkastet finns fritt tillgängligt på nätet redan nu, och den tryckta versionen kommer i början av nästa år. Materialet används redan på kurser vid flera lärosäten, och ligger till grund för kurser i R som jag ger i privat regi. Ta en titt om du är intresserad av vad R har att bjuda på!
I takt med att allt fler har drabbats eller tror sig ha drabbats av covid-19 så växer intresset för antikroppstester, som man hoppas ska visa om man har haft sjukdomen eller inte. Olika aktörer erbjuder olika sorters antikroppstester, och alla möjliga siffror nämns i sammanhanget: 99,2 % säkerhet, 93 % sensitivitet, 99 % specificitet – och så vidare. Vad innebär det egentligen – och kan man lita på testens resultat?
När medicinska tester utvärderas finns två mått som man brukar utgå från:
Sensitivitet: sannolikheten att testet ger ett positivt resultat för en person som har haft sjukdomen.
Specificitet: sannolikheten att testet ger ett negativt resultat för en person som inte har haft sjukdomen.
Man önskar sig att både sensitivitet och specificitet ska vara så höga som möjligt. Låg sensitivitet gör att många som har haft sjukdomen felaktig får beskedet att de inte har haft det, och låg specificitet gör att många som inte har haft sjukdomen felaktig får beskedet att de har haft den – vilket i fallet med coronaviruset förstås kan vara väldigt problematiskt. Tyvärr finns det inga tester som har 100 % sensitivitet och specificitet – det finns alltid en risk för ett felaktigt svar – men det finns tester som åtminstone kommer nära.
För att ta reda på hur hög sensitiviteten och specificiteten hos olika tester är behöver man göra studier där man använder testen dels på personer som har haft sjukdomen och dels på personer som inte har haft sjukdomen, och kontrollerar om testet gav rätt svar. Ett problem är att det krävs ett stort antal personer för att få en bra uppfattning om hur hög sensitiviteten och specificiteten hos ett test faktiskt är.
Ett exempel på svårigheterna kan ses i en uppmärksammad svensk studie där en forskargrupp från Uppsala universitet utvärderade så kallade snabbtest för antikroppar mot covid-19. Bland de 29 personer som haft sjukdomen fick 27 ett positivt testresultat, vilket motsvarar en sensitivitet på 27/29 = 93,1 %. Problemet är att när så pass få patienter undersöks så finns en risk att man råkar överskatta sensitiviteten – att man av ren slump råkade få fler positiva svar än vad man kan förvänta sig. Statistiska verktyg – hypotestester och konfidensintervall – kan då användas för att få ett mått på osäkerheten i resultaten. I det här fallet så är studiens resultat bara tillräckliga för att säga att sensitiviteten är högre än 74 %. Det finns alltså inga statistiska belägg för att säga att sensitiviteten inte är 75 %, 80 % eller 85 %. Vilket tyvärr inte hindrar företaget som säljer testet från att påstå att sensitiviteten är betydligt högre än så.
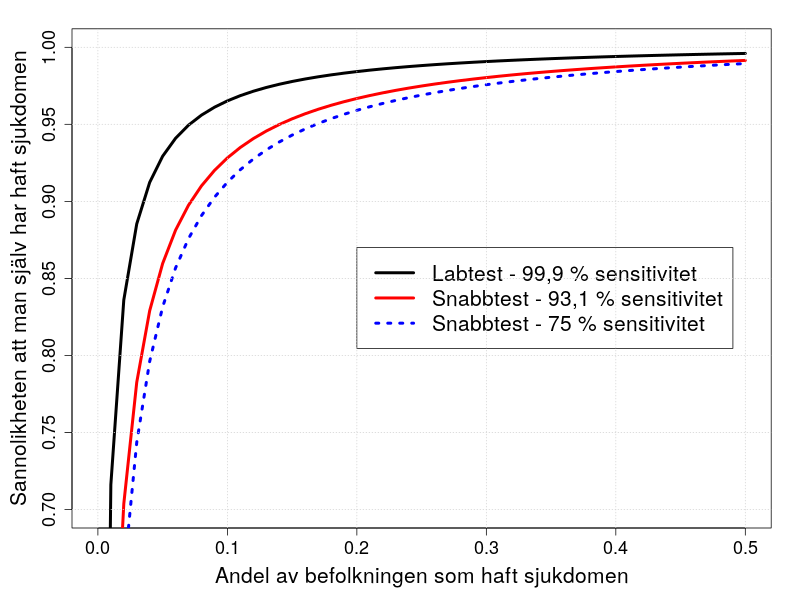
Vad betyder då resultaten man får från ett test? Svaret är att det beror på hur spridd sjukdomen är i befolkningen. Om ingen har haft sjukdomen så kommer exempelvis 100 % av de positiva resultaten att vara falska positiva, dvs. felaktiga positiva resultat. Ett labtest (som till skillnad från snabbtesten ger svar efter några dagar istället för efter några minuter) som används flitigt i Sverige uppges ha 99,6 % specificitet och 100 % sensitivitet (vilket knappast stämmer, så låt oss räkna med 99,9 % sensitivitet istället). Det innebär att om 1000 personer som inte haft sjukdomen testar sig så får 4 felaktigt ett positivt resultat, och om 1000 personer som har haft sjukdomen testar sig så får 1 felaktigt ett negativt resultat. Om man får ett positivt resultat och vet hur stor andel av befolkningen som har haft sjukdomen så kan man beräkna sannolikheten att man själv har haft den:
Om 7 % av befolkningen i en region har haft sjukdomen så kommer 95 % av de som får ett positivt resultat i ett labtest att ha haft sjukdomen, och 90 % av de som får ett positivt resultat i ett snabbtest. Om 20 % har haft sjukdomen blir motsvarande siffror 98,4 % och 96,7 %. Ett positivt resultat betyder alltså att det är troligt, men inte säkert, att man har haft sjukdomen. (Jag utgår då från att personer som haft och inte haft sjukdomen är lika benägna att testa sig.)
Inte krångligt nog? I fallet med covid-19 har det visat sig att många personer inte utvecklar antikroppar efter genomgången infektion, vilket gör resultaten av antikroppstesten ännu osäkrare. Fortfarande inte krångligt nog? I så fall kan det vara bra att ha i åtanke att antikroppar inte är samma sak som immunitet. Man kan ha antikroppar mot en sjukdom utan att vara (fullständigt) immun eller vara immun mot en sjukdom utan att ha antikroppar – de är bara ett av immunförsvarets verktyg mot virus. Ett negativt antikroppstest behöver därför inte nödvändigtvis betyda att man inte är immun, på samma sätt som att ett positivt resultat inte behöver betyda att man är immun eller inte kan sprida smittan till andra. Det finns fortfarande mycket vi inte vet om covid-19, och tills vidare finns inget annat att göra än att fortsätta följa Folkhälsomyndighetens rekommendationer – oavsett resultatet på ditt antikroppstest.
Jag erbjuder konsulttjänster, föredrag och utbildningar inom statistik – bland annat kring hur studier kan utvärderas. Kontakta mig för att få veta mer.
Coronaviruset har påverkat alla delar av samhället – inklusive sportens värld. I Sverige fick bland annat innebandyns slutspel ställas in. Serievinnarna IKSU (dam) och Falun (herr) tilldelades SM-guldet. Men hur sannolikt är det egentligen att de faktiskt hade vunnit slutspelet?
Jag har för Innebandymagazinets räkning tagit fram en modell som förutspår hur innebandyns slutspel borde ha slutat. Modellen bygger på matchresultat från de senaste två säsongerna och tar med olika parametrar hänsyn till hur bra de olika lagen är, dels på hemmaplan och dels på bortaplan. Med hjälp av modellen kunde jag sedan simulera slutspelet 1 000 000 gånger, för att se hur troliga olika resultat var.
Det finns mycket som påverkar resultatet i en match, och allt kan inte sammanfattas med siffror. Men däremot är det fullt möjligt att skapa modeller som säger hur sannolikt det är att olika lag vinner, samt vilka resultat som är mest troliga. Och det fungerar faktiskt – när vi testade min modell på förra årets herrslutspel så prickade den in rätt vinnare i samtliga kvarts- och semifinaler.
Innebandymagazinet kommer att släppa resultatet som modellen förutspår dag för dag fram till det som skulle ha varit finaldagen – den 25e april. För egen del ser jag fram emot att läsa vad spelare och tränare tycker och tänker om modellens resultat. De första artiklarna finns uppe redan nu:
I skuggan av klimatförändringar är antibiotikaresistens en av 2000-talets stora utmaningar. En ljusglimt kom häromveckan, när en artikel publicerades där forskare vid bland annat MIT beskrev hur de använt AI och maskininlärning för att upptäcka nya antibiotika som i djurstudier visat sig bita på multiresistenta bakterier. Artikeln finns här; en mer lättsmält rapport finns att läsa i The Guardian. Upptäckten har lyfts fram som början på en ny era för läkemedelsforskningen, där AI kommer att ge oss framtidens läkemedel. Liknande metoder har redan börjat användas för att ta fram läkemedel mot coronaviruset.
Men hur gör man egentligen för att få AI att upptäcka nya läkemedel?
AI och maskininlärning handlar i grund och botten om att låta datorn ta fram komplicerade matematiska formler (ofta många sidor långa) som kan användas för att lösa problem. Vill man exempelvis lära datorn att översätta text måste man då först förse den med en massa exempel på översatta texter. Formlerna byggs upp genom att datorn går igenom de här exemplen för att hitta mönster. När de är klara kan man stoppa in någon sorts data i formeln och få ut ett svar. Om systemet byggts för översättningar stoppar man in en text och får ut en översättning av texten till ett annat språk. Om det har byggts för att beskriva bilder stoppar man in en bild och får ut en beskrivning av vad bilden föreställer.
Kan då samma idé användas för att hitta nya antibiotika? Svaret är ja. Vi känner idag till hundratals miljoner molekyler, men bara en liten bråkdel av dem har testats som läkemedel. En idé vore därför att bygga ett AI-system som kan känna igen hur antibiotikamolekyler ser ut och låta det gå igenom listan över kända molekyler för att bedöma om dessa kan användas som antibiotika eller inte.
Det är precis vad forskarna vid MIT gjorde i sitt projekt. De samlade ihop data om drygt 2300 molekyler, varav några gick att använda som antibiotika vid behandling av vissa bakterieinfektioner. De exemplen kunde de sedan använda för att bygga ett AI-system som utifrån information om en molekyls struktur kunde förutsäga om molekylen fungerade som antibiotika eller inte. Inte med hundraprocentig noggrannhet, men med tillräckligt hög noggrannhet för att oftast ha rätt. Forskarna lät därefter systemet gå igenom mer än 100 miljoner kända molekyler och bedöma hur sannolikt det var att dessa skulle gå att använda som antibiotika. Slutligen testade de om de 99 molekyler som systemet ansåg vara mest lovande faktiskt hade någon antibiotisk verkan i laboratorieförsök. 63 av dem visade sig ha det.
En av molekylerna, kallad halicin, verkar särskilt lovande. I försök med möss har forskarna sett att läkemedlet, som inte är likt de antibiotika som används idag, är effektivt mot flera multiresistenta bakterier.
Den stora fördelen med AI är sällan att systemen utför uppgifter bättre än oss, utan att de kan utföra uppgifter mycket snabbare än vad människor hade klarat av. Textöversättning är ett bra exempel på det – tjänster som Google Översätt ger blixtsnabba översättningar. De blir inte alltid rätt och håller inte samma kvalitet som omsorgsfullt gjorda översättningar av professionella mänskliga översättare, men är ofta bra nog. Den här snabbheten var helt avgörande för antibiotikaprojektet vid MIT. Ingen forskargrupp på jorden hade kunnat testa sig igenom 100 miljoner molekyler, men AI-systemet kunde göra det på några timmar. Det gav inte rätt svar för varje molekyl, men för tillräckligt många för att vara användbart. Det är, åtminstone i det här fallet, gott nog.
Dagens AI ligger långt ifrån de superintelligenta robotar vi stöter på i science fiction. Men redan nu kan vi använda AI för att automatisera vissa uppgifter som lämpar sig särskilt bra för datorer. Det kan göra att projekt som skulle ta årtionden blir klara på några veckor. Det öppnar nya möjligheter och frigör tid, och rätt använt låter det oss människor fokusera på andra mer intressanta arbetsuppgifter. AI som ett verktyg i läkemedelsutveckling är inte science fiction – det är kort och gott science.
Uppdatering april 2020: Texten nedan skrevs i början av februari, innan det nya coronaviruset på allvar börjat spridas utanför Kina. Den handlar om hur AI kan användas för att upptäcka och bekämpa epidemier i ett tidigt skede snarare än när man fått stor samhällsspridning, och handlar därför inte om det allvarligare läge som många länder nu befinner sig i.
De senaste veckorna har nyhetsrapporteringen dominerats av spridningen av coronaviruset 2019-nCov. Ett ord som dyker upp gång på gång i de spaltmeter som skrivits om viruset är AI, och rapporteringen låter oss se vilka kliv utvecklingen inom AI tagit det senaste årtiondet. Det vi ser är imponerande.
Smittspridningen blev allmänt känd först i januari, även om den nu tros ha pågått sedan december. Redan då varnade det kanadensiska bolaget BlueDot sina kunder för att deras AI-system, som samlar in data från mängder av digitala källor, upptäckt spridningen av ett nytt virus i kinesiska Wuhan.
Men AI används inte bara för att kunna förutse hur epidemier sprider sig. Tvärtom så används AI för att bekämpa spridningen på flera olika sätt:
AI-drivna botar har ringt upp Shanghaibor hörandes till riskgrupper och frågat dem om symptom. I en del fall har de rekommenderats karantän i hemmet, och botarna har då informerat myndigheterna om de misstänkta fallen. En bot kan genomföra 200 sådana samtal på 5 minuter, medan en människa hade behövt 2-3 timmar för att göra motsvarande jobb. Med AI kan myndigheterna snabbt nå ett stort antal människor under kriser.
Autonoma robotar används för att desinficera slutna delar av sjukhus och servera mat till personer som satts i karantän. AI kan ta över farliga uppdrag från människor för att minska smittorisken.
Stora kinesiska teknikbolag som Baidu och Alibaba har delat med sig av AI-algoritmer och datorkraft för att förstå virusets genetik, vilket snabbat upp processen flera gånger om.
AI har använts för att ta fram kandidatmolekyler för läkemedel mot coronaviruset. Det gör att läkemedel förhoppningsvis kan tas fram på mycket kortare tid.
En titt på rapporteringen kring coronaviruset gör det tydligt att AI är inte längre science fiction, utan något som används överallt hela tiden. Vi stöter på AI varje dag i nätbutikers och strömningstjänsters rekommendationer, kartappar, skräppostfilter, kamerafilter och röstassistenter som Google Home och Siri. Samtidigt är den här en teknologi som fortfarande är ung, och som dras med problem som inbyggd diskriminering och bristande genomskinlighet. Att ha en grundläggande förståelse för AIblir allt viktigare för allt fler, dels för att förstå teknikens möjligheter och dels för att förstå dess begränsningar.