I november gav jag en kurs om machine learning och AI för forskare som tillhör EpiHealth – ett svenskt forskningsnätverk som ägnar sig åt epidemiologisk forskning för att bättre förstå utbredning och bakomliggande orsaker till olika sjukdomar.
What was the most important lesson? – That machine learning is more accessible than I thought! The course provided a broad introduction to different methods – everything from classic regression models to advanced neural networks. We also got to try applying them in practice, which will really help when I implement the methods on my own. In addition to new knowledge, I take with me the insight that these tools are fully possible to use even for researchers without a technical background and that they can open completely new doors for epidemiological research. The idea workshop was in full swing on the train home, and I am now looking forward to implementing what I learned in my own research.
Jag jobbar med den här sortens modeller varje dag, och det är minst sagt spännande att följa utvecklingen som sker just nu. Med moderna verktyg är maskininlärning och AI tillgängligare än någonsin. Den mest intressanta utvecklingen, den som faktiskt gör skillnad för beslutsfattande och forskning, har ingenting med ChatGPT att göra. Istället är det ofta helt andra modeller som används. Om det, och mycket annat, handlade den här kursen.
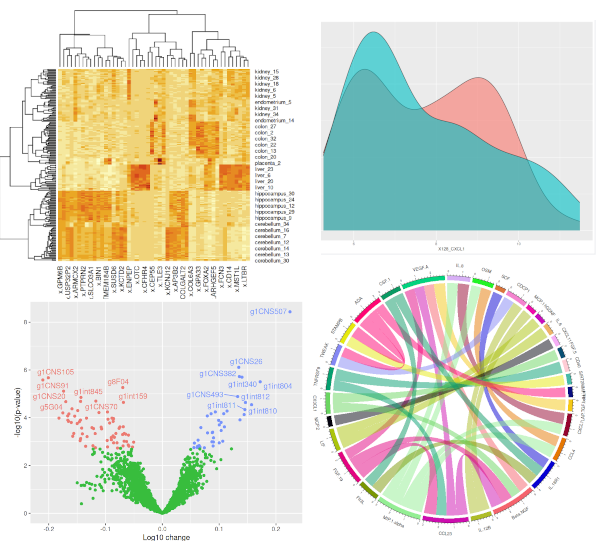
Ett problem som jag återkommit till många gånger genom åren, både som forskare och som konsult, är statistisk analys av biomarkörsdata. Biomarkörer är mätvärden från exempelvis blodprov, som beskriver mängden av till exempel olika proteiner eller molekyler. De är en viktig del av modern medicin, och används flitigt inom medicinsk forskning, där man letar efter biomarkörer som går att använda för att diagnosticera sjukdomar, ge prognoser för risken att drabbas av en sjukdom, eller för att förstås mekanismerna bakom olika åkommor.
Biomarkörsdata kännetecknas av en rad utmaningar: många variabler men få observationer, data som inte är normalfördelade, mätvärden som ligger under mätteknikens detektionsgräns. Det här kräver specialiserade statistiska metoder. Om det handlar ena dagen i min nya tvådagarskurs om medicinsk statistik. Den andra dagen fokuserar på överlevnadsanalys.
Intresserad av att lära dig mer om moderna statistiska metoder inom medicin? Ta en titt på årets kursdatum eller kontakta mig för att boka en kurs på plats hos er.
Den andra utgåvan av min bok Modern Statistics with R har nu släppts. Den handlar om allt från grundläggande statistiska koncept till R-programmering, avancerade regressionsmodeller och machine learning. Boken går att läsa gratis på nätet eller köpa i fysisk form i bokhandlar (utgiven internationellt av CRC Press).
Förutom att Modern Statistics with R används som kurslitteratur på universitet världen över så ligger den också till grund för de R-kurser jag ger i samarbete med Statistikakademin. Intresserad av att lära dig mer om R, statistik, machine learning eller AI? Ta en titt på höstens och vårens kursdatum eller kontakta mig för att boka en kurs på plats hos er.
I takt med att allt fler har drabbats eller tror sig ha drabbats av covid-19 så växer intresset för antikroppstester, som man hoppas ska visa om man har haft sjukdomen eller inte. Olika aktörer erbjuder olika sorters antikroppstester, och alla möjliga siffror nämns i sammanhanget: 99,2 % säkerhet, 93 % sensitivitet, 99 % specificitet – och så vidare. Vad innebär det egentligen – och kan man lita på testens resultat?
När medicinska tester utvärderas finns två mått som man brukar utgå från:
Sensitivitet: sannolikheten att testet ger ett positivt resultat för en person som har haft sjukdomen.
Specificitet: sannolikheten att testet ger ett negativt resultat för en person som inte har haft sjukdomen.
Man önskar sig att både sensitivitet och specificitet ska vara så höga som möjligt. Låg sensitivitet gör att många som har haft sjukdomen felaktig får beskedet att de inte har haft det, och låg specificitet gör att många som inte har haft sjukdomen felaktig får beskedet att de har haft den – vilket i fallet med coronaviruset förstås kan vara väldigt problematiskt. Tyvärr finns det inga tester som har 100 % sensitivitet och specificitet – det finns alltid en risk för ett felaktigt svar – men det finns tester som åtminstone kommer nära.
För att ta reda på hur hög sensitiviteten och specificiteten hos olika tester är behöver man göra studier där man använder testen dels på personer som har haft sjukdomen och dels på personer som inte har haft sjukdomen, och kontrollerar om testet gav rätt svar. Ett problem är att det krävs ett stort antal personer för att få en bra uppfattning om hur hög sensitiviteten och specificiteten hos ett test faktiskt är.
Ett exempel på svårigheterna kan ses i en uppmärksammad svensk studie där en forskargrupp från Uppsala universitet utvärderade så kallade snabbtest för antikroppar mot covid-19. Bland de 29 personer som haft sjukdomen fick 27 ett positivt testresultat, vilket motsvarar en sensitivitet på 27/29 = 93,1 %. Problemet är att när så pass få patienter undersöks så finns en risk att man råkar överskatta sensitiviteten – att man av ren slump råkade få fler positiva svar än vad man kan förvänta sig. Statistiska verktyg – hypotestester och konfidensintervall – kan då användas för att få ett mått på osäkerheten i resultaten. I det här fallet så är studiens resultat bara tillräckliga för att säga att sensitiviteten är högre än 74 %. Det finns alltså inga statistiska belägg för att säga att sensitiviteten inte är 75 %, 80 % eller 85 %. Vilket tyvärr inte hindrar företaget som säljer testet från att påstå att sensitiviteten är betydligt högre än så.
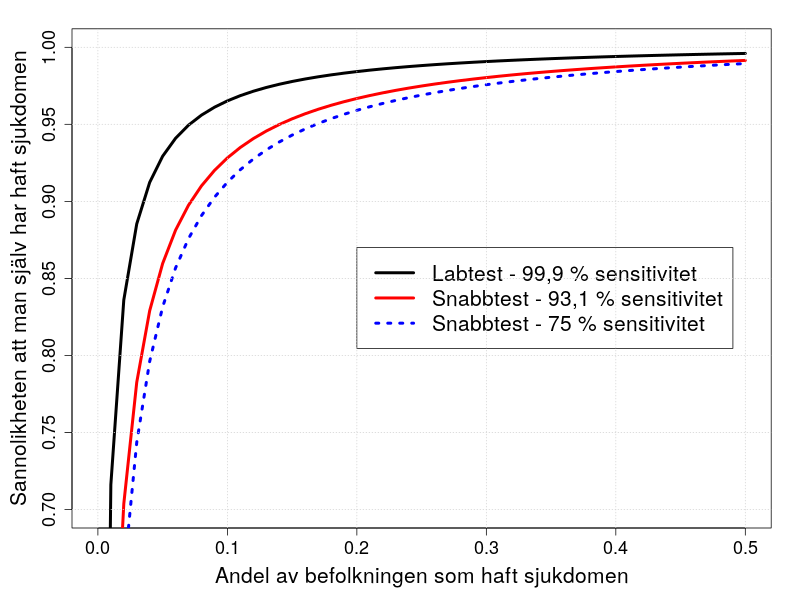
Vad betyder då resultaten man får från ett test? Svaret är att det beror på hur spridd sjukdomen är i befolkningen. Om ingen har haft sjukdomen så kommer exempelvis 100 % av de positiva resultaten att vara falska positiva, dvs. felaktiga positiva resultat. Ett labtest (som till skillnad från snabbtesten ger svar efter några dagar istället för efter några minuter) som används flitigt i Sverige uppges ha 99,6 % specificitet och 100 % sensitivitet (vilket knappast stämmer, så låt oss räkna med 99,9 % sensitivitet istället). Det innebär att om 1000 personer som inte haft sjukdomen testar sig så får 4 felaktigt ett positivt resultat, och om 1000 personer som har haft sjukdomen testar sig så får 1 felaktigt ett negativt resultat. Om man får ett positivt resultat och vet hur stor andel av befolkningen som har haft sjukdomen så kan man beräkna sannolikheten att man själv har haft den:
Om 7 % av befolkningen i en region har haft sjukdomen så kommer 95 % av de som får ett positivt resultat i ett labtest att ha haft sjukdomen, och 90 % av de som får ett positivt resultat i ett snabbtest. Om 20 % har haft sjukdomen blir motsvarande siffror 98,4 % och 96,7 %. Ett positivt resultat betyder alltså att det är troligt, men inte säkert, att man har haft sjukdomen. (Jag utgår då från att personer som haft och inte haft sjukdomen är lika benägna att testa sig.)
Inte krångligt nog? I fallet med covid-19 har det visat sig att många personer inte utvecklar antikroppar efter genomgången infektion, vilket gör resultaten av antikroppstesten ännu osäkrare. Fortfarande inte krångligt nog? I så fall kan det vara bra att ha i åtanke att antikroppar inte är samma sak som immunitet. Man kan ha antikroppar mot en sjukdom utan att vara (fullständigt) immun eller vara immun mot en sjukdom utan att ha antikroppar – de är bara ett av immunförsvarets verktyg mot virus. Ett negativt antikroppstest behöver därför inte nödvändigtvis betyda att man inte är immun, på samma sätt som att ett positivt resultat inte behöver betyda att man är immun eller inte kan sprida smittan till andra. Det finns fortfarande mycket vi inte vet om covid-19, och tills vidare finns inget annat att göra än att fortsätta följa Folkhälsomyndighetens rekommendationer – oavsett resultatet på ditt antikroppstest.
Jag erbjuder konsulttjänster, föredrag och utbildningar inom statistik – bland annat kring hur studier kan utvärderas. Kontakta mig för att få veta mer.
I våras hjälpte jag Dairy Data Warehouse att utveckla olika prognossystem för mjölkindustrin. I förra veckan lanserades några av de här systemen på den ledande mässan inom djurhållning: EuroTier i Hannover. De system jag varit med och utvecklat använder AI i form av djupinlärning (deep learning), där data från en rad olika källor (mjölkningsrobotar, fodersystem, avelsdatabaser, m.m.) vägs ihop för att göra prognoser för exempelvis hur mycket mjölk en ko kommer att ge det närmaste året.
Systemen kommer att kunna användas på flera olika sätt. Bonden kommer att få bättre underlag för att bedöma vilka djur hon ska behålla och för hur ekonomin kommer se ut framöver. Mejerierna kommer att få bättre uppskattningar av hur mycket mjölk de ska hämta olika dagar och kan därmed bättre planera de rutter som tankbilarna åker, med både ekonomiska och miljömässiga vinster.
Dagens mjölkindustri är teknikintensiv och full av system som samlar in data av olika slag. Dairy Data Warehouse har byggt upp en unik databas där data från alla dessa system samlas på ett och samma ställe. Med hjälp av den databasen har vi också utvecklat system som ska ge bättre djurhälsa och som knyter an till internet of things i ladugården och på mejeriet. Mer om det kommer en annan gång.
Jag erbjuder rådgivning och utvecklingstjänster kring prognoser och AI. Kontakta mig för att få veta mer.