I november gav jag en kurs om machine learning och AI för forskare som tillhör EpiHealth – ett svenskt forskningsnätverk som ägnar sig åt epidemiologisk forskning för att bättre förstå utbredning och bakomliggande orsaker till olika sjukdomar.
What was the most important lesson? – That machine learning is more accessible than I thought! The course provided a broad introduction to different methods – everything from classic regression models to advanced neural networks. We also got to try applying them in practice, which will really help when I implement the methods on my own. In addition to new knowledge, I take with me the insight that these tools are fully possible to use even for researchers without a technical background and that they can open completely new doors for epidemiological research. The idea workshop was in full swing on the train home, and I am now looking forward to implementing what I learned in my own research.
Jag jobbar med den här sortens modeller varje dag, och det är minst sagt spännande att följa utvecklingen som sker just nu. Med moderna verktyg är maskininlärning och AI tillgängligare än någonsin. Den mest intressanta utvecklingen, den som faktiskt gör skillnad för beslutsfattande och forskning, har ingenting med ChatGPT att göra. Istället är det ofta helt andra modeller som används. Om det, och mycket annat, handlade den här kursen.
Ett problem som jag återkommit till många gånger genom åren, både som forskare och som konsult, är statistisk analys av biomarkörsdata. Biomarkörer är mätvärden från exempelvis blodprov, som beskriver mängden av till exempel olika proteiner eller molekyler. De är en viktig del av modern medicin, och används flitigt inom medicinsk forskning, där man letar efter biomarkörer som går att använda för att diagnosticera sjukdomar, ge prognoser för risken att drabbas av en sjukdom, eller för att förstås mekanismerna bakom olika åkommor.
Biomarkörsdata kännetecknas av en rad utmaningar: många variabler men få observationer, data som inte är normalfördelade, mätvärden som ligger under mätteknikens detektionsgräns. Det här kräver specialiserade statistiska metoder. Om det handlar ena dagen i min nya tvådagarskurs om medicinsk statistik. Den andra dagen fokuserar på överlevnadsanalys.
Intresserad av att lära dig mer om moderna statistiska metoder inom medicin? Ta en titt på årets kursdatum eller kontakta mig för att boka en kurs på plats hos er.
I skuggan av klimatförändringar är antibiotikaresistens en av 2000-talets stora utmaningar. En ljusglimt kom häromveckan, när en artikel publicerades där forskare vid bland annat MIT beskrev hur de använt AI och maskininlärning för att upptäcka nya antibiotika som i djurstudier visat sig bita på multiresistenta bakterier. Artikeln finns här; en mer lättsmält rapport finns att läsa i The Guardian. Upptäckten har lyfts fram som början på en ny era för läkemedelsforskningen, där AI kommer att ge oss framtidens läkemedel. Liknande metoder har redan börjat användas för att ta fram läkemedel mot coronaviruset.
Men hur gör man egentligen för att få AI att upptäcka nya läkemedel?
AI och maskininlärning handlar i grund och botten om att låta datorn ta fram komplicerade matematiska formler (ofta många sidor långa) som kan användas för att lösa problem. Vill man exempelvis lära datorn att översätta text måste man då först förse den med en massa exempel på översatta texter. Formlerna byggs upp genom att datorn går igenom de här exemplen för att hitta mönster. När de är klara kan man stoppa in någon sorts data i formeln och få ut ett svar. Om systemet byggts för översättningar stoppar man in en text och får ut en översättning av texten till ett annat språk. Om det har byggts för att beskriva bilder stoppar man in en bild och får ut en beskrivning av vad bilden föreställer.
Kan då samma idé användas för att hitta nya antibiotika? Svaret är ja. Vi känner idag till hundratals miljoner molekyler, men bara en liten bråkdel av dem har testats som läkemedel. En idé vore därför att bygga ett AI-system som kan känna igen hur antibiotikamolekyler ser ut och låta det gå igenom listan över kända molekyler för att bedöma om dessa kan användas som antibiotika eller inte.
Det är precis vad forskarna vid MIT gjorde i sitt projekt. De samlade ihop data om drygt 2300 molekyler, varav några gick att använda som antibiotika vid behandling av vissa bakterieinfektioner. De exemplen kunde de sedan använda för att bygga ett AI-system som utifrån information om en molekyls struktur kunde förutsäga om molekylen fungerade som antibiotika eller inte. Inte med hundraprocentig noggrannhet, men med tillräckligt hög noggrannhet för att oftast ha rätt. Forskarna lät därefter systemet gå igenom mer än 100 miljoner kända molekyler och bedöma hur sannolikt det var att dessa skulle gå att använda som antibiotika. Slutligen testade de om de 99 molekyler som systemet ansåg vara mest lovande faktiskt hade någon antibiotisk verkan i laboratorieförsök. 63 av dem visade sig ha det.
En av molekylerna, kallad halicin, verkar särskilt lovande. I försök med möss har forskarna sett att läkemedlet, som inte är likt de antibiotika som används idag, är effektivt mot flera multiresistenta bakterier.
Den stora fördelen med AI är sällan att systemen utför uppgifter bättre än oss, utan att de kan utföra uppgifter mycket snabbare än vad människor hade klarat av. Textöversättning är ett bra exempel på det – tjänster som Google Översätt ger blixtsnabba översättningar. De blir inte alltid rätt och håller inte samma kvalitet som omsorgsfullt gjorda översättningar av professionella mänskliga översättare, men är ofta bra nog. Den här snabbheten var helt avgörande för antibiotikaprojektet vid MIT. Ingen forskargrupp på jorden hade kunnat testa sig igenom 100 miljoner molekyler, men AI-systemet kunde göra det på några timmar. Det gav inte rätt svar för varje molekyl, men för tillräckligt många för att vara användbart. Det är, åtminstone i det här fallet, gott nog.
Dagens AI ligger långt ifrån de superintelligenta robotar vi stöter på i science fiction. Men redan nu kan vi använda AI för att automatisera vissa uppgifter som lämpar sig särskilt bra för datorer. Det kan göra att projekt som skulle ta årtionden blir klara på några veckor. Det öppnar nya möjligheter och frigör tid, och rätt använt låter det oss människor fokusera på andra mer intressanta arbetsuppgifter. AI som ett verktyg i läkemedelsutveckling är inte science fiction – det är kort och gott science.
Uppdatering april 2020: Texten nedan skrevs i början av februari, innan det nya coronaviruset på allvar börjat spridas utanför Kina. Den handlar om hur AI kan användas för att upptäcka och bekämpa epidemier i ett tidigt skede snarare än när man fått stor samhällsspridning, och handlar därför inte om det allvarligare läge som många länder nu befinner sig i.
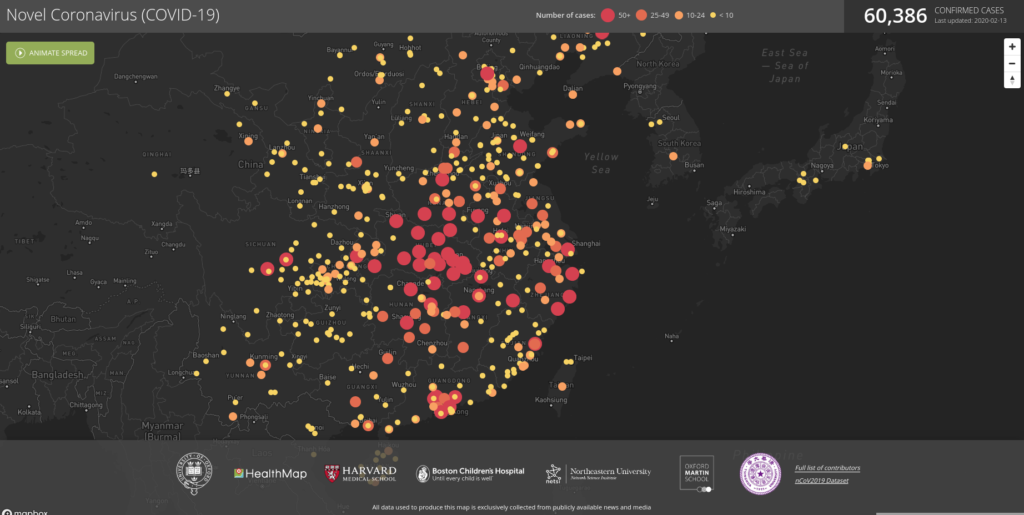
De senaste veckorna har nyhetsrapporteringen dominerats av spridningen av coronaviruset 2019-nCov. Ett ord som dyker upp gång på gång i de spaltmeter som skrivits om viruset är AI, och rapporteringen låter oss se vilka kliv utvecklingen inom AI tagit det senaste årtiondet. Det vi ser är imponerande.
Smittspridningen blev allmänt känd först i januari, även om den nu tros ha pågått sedan december. Redan då varnade det kanadensiska bolaget BlueDot sina kunder för att deras AI-system, som samlar in data från mängder av digitala källor, upptäckt spridningen av ett nytt virus i kinesiska Wuhan.
Men AI används inte bara för att kunna förutse hur epidemier sprider sig. Tvärtom så används AI för att bekämpa spridningen på flera olika sätt:
AI-drivna botar har ringt upp Shanghaibor hörandes till riskgrupper och frågat dem om symptom. I en del fall har de rekommenderats karantän i hemmet, och botarna har då informerat myndigheterna om de misstänkta fallen. En bot kan genomföra 200 sådana samtal på 5 minuter, medan en människa hade behövt 2-3 timmar för att göra motsvarande jobb. Med AI kan myndigheterna snabbt nå ett stort antal människor under kriser.
Autonoma robotar används för att desinficera slutna delar av sjukhus och servera mat till personer som satts i karantän. AI kan ta över farliga uppdrag från människor för att minska smittorisken.
Stora kinesiska teknikbolag som Baidu och Alibaba har delat med sig av AI-algoritmer och datorkraft för att förstå virusets genetik, vilket snabbat upp processen flera gånger om.
AI har använts för att ta fram kandidatmolekyler för läkemedel mot coronaviruset. Det gör att läkemedel förhoppningsvis kan tas fram på mycket kortare tid.
En titt på rapporteringen kring coronaviruset gör det tydligt att AI är inte längre science fiction, utan något som används överallt hela tiden. Vi stöter på AI varje dag i nätbutikers och strömningstjänsters rekommendationer, kartappar, skräppostfilter, kamerafilter och röstassistenter som Google Home och Siri. Samtidigt är den här en teknologi som fortfarande är ung, och som dras med problem som inbyggd diskriminering och bristande genomskinlighet. Att ha en grundläggande förståelse för AIblir allt viktigare för allt fler, dels för att förstå teknikens möjligheter och dels för att förstå dess begränsningar.
e-hälsa och digitalisering av vården är 2010-talets melodi och nu börjar vi på allvar se fördelarna med det inom medicinsk diagnostik. Ta patienter som hamnar på sjukhus som ett exempel. Genom åren har flera statistiska modeller för att förutspå mortalitet, oplanerade återbesök och långvarig inläggning på sjukhus tagits fram. Genom att använda information om exempelvis blodtryck, puls, andning och vita blodkroppar kan modellerna med hyfsad noggrannhet avgöra risken att en patient avlider, tvingas komma tillbaka till sjukhuset eller blir kvar i mer än en vecka.
I en intressant artikel från maj i år visar forskare från bland annat Google och Stanford att ett AI-system som kan läsa digitala journaler gör ett betydligt bättre jobb när det gäller att förutspå sådana risker. Artikeln har uppmärksammats stort i media, bland annat av Daily Mail och Bloomberg. Studien ser ut som en triumf för e-hälsa och forskarna ägnar mycket utrymme åt att beskriva fördelarna med djupinlärning, som är den form av AI de använt.
Det är lätt att hålla med om att det här är ett stort kliv framåt för e-hälsa – det visar att datorsystem som tolkar hela journaler istället för några få mätvärden har stor potential. Däremot är det knappast något stort kliv framåt för AI. Den som läser artikeln lite närmare hittar nämligen en jämförelse mellan forskarnas djupinlärningssystem och ett betydligt enklare system som matats med samma journaldata. Det senare använder logistisk regression – en stapelvara inom traditionell statistisk analys, som lärs ut på grundkurser och har funnits sedan 1950-talet. Jämförelsen, som ligger gömd längst ner i artikelns appendix, visar att skillnaden mellan djupinlärning och logistisk regression är minimal (och ser ut att vara inom felmarginalen).
Att lära upp djupinlärningssystem är tidskrävande och kräver mängder av beräkningskraft. Logistisk regression är betydligt enklare att använda, kräver mindre datorkraft och har dessutom fördelen att modellen går att tolka: djupinlärningssystem är så kallade svarta lådor där vi inte vet varför de gör en viss bedömning, medan vi med logistisk regression kan förstå precis varför systemet gör bedömningen. Om båda systemen fungerar lika bra så ska man välja logistisk regression alla dagar i veckan. En produkt som inget vet hur den fungerar är förstås inte lika bra som en produkt som vi kan förstå.
I den här och liknande artiklar kan man just nu skönja två tendenser:
e-hälsa kommer fortsätta leda till förbättrad vård och smart användning av digitala journaler kommer leda till bättre diagnoser.
Alla vill hoppa på AI-tåget och det är lätt att bli förblindad av alla glänsande nya AI-verktyg. Det verkliga bidraget i den här artikeln är sättet att få ut information från digitala journaler – inte användet av djupinlärning. Trots det talar både forskarna och media mest om AI-aspekten.
Den dataanalys som använder de häftigaste senaste teknikerna är inte alltid den som är bäst. Det är något som är väl värt att ha i åtanke när ni anlitar konsulter för dataanalys. Ibland är AI och djupinlärning precis rätt verktyg för era problem, men ibland är andra alternativ mycket bättre. Precis som man ska vara försiktig med att anlita en snickare som tror sig kunna lösa alla byggprojekt med bara en hammare så ska man tänka sig för innan man anlitar en konsult som vill lösa alla problem med AI.