Vi är inte direkt bortskämda med populärvetenskapliga böcker, tv-program och poddar om statistik. Nu gör Sveriges radio en insats på området med programmet Vilse i statistiken, där professor Tom Britton (känd för sina tålmodiga förklaringar av covidstatistik under pandemin) agerar expert. Avsnitten är runt tio minuter långa och går att höra på radion, på sverigesradio.se och där poddar finns.
Ett annat fint exempel på svenskledd populärstatistik är (den nu mer än tio år gamla) dokumentären The Joy of Stats med Hans Rosling, som finns på Gapminders webbplats.
En favorit på området är annars den norska dokumentärserien Siffer, som handlar om statistik, sannolikhetslära och matematik. Några av avsnitten finns på seriens Youtubesida.
Idag drar fotbolls-EM för herrar igång – ett år försenat. Många sitter nog just nu och försöker tippa resultaten. Somliga lusläser fotbollsstatistik, andra går på magkänslan, och någon kanske gör som jag gjorde för det svenska innebandyslutspelet förra året och tar fram en statistisk prediktionsmodell.
Men det finns en metod som är bättre än alla ovanstående: att låta en bläckfisk tippa resultaten. Bläckfisken Paul vid Sea Life Center i tyska Oberhausen blev en internationell kändis under fotbolls-VM 2010, då han tippade rätt i 8 av 8 matcher.
Hade Paul bara tur, eller var han ett tipsorakel av rang? Ett vanligt sätt att statistiskt utvärdera en hypotes är p-värden. De mäter hur starka bevisen för att en hypotes är felaktig är. Hypotesen som testas brukar kallas nollhypotesen. Om nollhypotesen inte stämmer så gäller istället en alternativhypotes. Den något torra definition av p-värdet är att det är sannolikheten för ett resultat som är minst lika extremt som det observerade, i riktning mot alternativhypotesen. Om p-värden hamnar under en på förhand bestämd gräns – ofta 0,05 – så säger man att resultatet är signifikant eller statistiskt säkerställt och anser sig ha belägg för att det är alternativhypotesen som stämmer.
I fallet med bläckfisken Paul så kan vi undersöka nollhypotesen att Paul bara gissade blint. Alternativhypotesen är att han på något sätt faktiskt kunde förutse resultaten i matcherna. Om vi även räknar in de matcher han tippade i EM 2008 (4 rätt på 6 matcher) så har vi att han tippade rätt i 12 matcher av 14 möjliga. p-värdet blir då sannolikheten att tippa minst 12 rätt (”ett resultat som är minst lika extremt som det observerade”) när man tippar 14 matcher. Om nollhypotesen stämmer så borde Paul ha samma chans att tippa rätt som man skulle få om man singlade slant. Vi kan då räkna ut p-värdet, som blir 0,0065. Det ligger långt under gränsen 0,05 och därmed är det alltså statistiskt säkerställt att Paul hade förmågan att förutse resultaten i fotbollsmatcher.
Det finns två slutsatser man kan dra av exemplet med Paul. Den första slutsatsen är att man aldrig ska nöja sig med en enda studie som visar att något är statistisk säkerställt. Det finns alltid en risk att p-värdet blir lågt av ren slump, datafel, felräkningar eller brister i försöksupplägget. Därför behövs nya försök och upprepningar av studier innan man kan säga något med säkerhet.
Den andra slutsatsen? Man ska aldrig underskatta en bläckfisk.
I takt med att allt fler har drabbats eller tror sig ha drabbats av covid-19 så växer intresset för antikroppstester, som man hoppas ska visa om man har haft sjukdomen eller inte. Olika aktörer erbjuder olika sorters antikroppstester, och alla möjliga siffror nämns i sammanhanget: 99,2 % säkerhet, 93 % sensitivitet, 99 % specificitet – och så vidare. Vad innebär det egentligen – och kan man lita på testens resultat?
När medicinska tester utvärderas finns två mått som man brukar utgå från:
Sensitivitet: sannolikheten att testet ger ett positivt resultat för en person som har haft sjukdomen.
Specificitet: sannolikheten att testet ger ett negativt resultat för en person som inte har haft sjukdomen.
Man önskar sig att både sensitivitet och specificitet ska vara så höga som möjligt. Låg sensitivitet gör att många som har haft sjukdomen felaktig får beskedet att de inte har haft det, och låg specificitet gör att många som inte har haft sjukdomen felaktig får beskedet att de har haft den – vilket i fallet med coronaviruset förstås kan vara väldigt problematiskt. Tyvärr finns det inga tester som har 100 % sensitivitet och specificitet – det finns alltid en risk för ett felaktigt svar – men det finns tester som åtminstone kommer nära.
För att ta reda på hur hög sensitiviteten och specificiteten hos olika tester är behöver man göra studier där man använder testen dels på personer som har haft sjukdomen och dels på personer som inte har haft sjukdomen, och kontrollerar om testet gav rätt svar. Ett problem är att det krävs ett stort antal personer för att få en bra uppfattning om hur hög sensitiviteten och specificiteten hos ett test faktiskt är.
Ett exempel på svårigheterna kan ses i en uppmärksammad svensk studie där en forskargrupp från Uppsala universitet utvärderade så kallade snabbtest för antikroppar mot covid-19. Bland de 29 personer som haft sjukdomen fick 27 ett positivt testresultat, vilket motsvarar en sensitivitet på 27/29 = 93,1 %. Problemet är att när så pass få patienter undersöks så finns en risk att man råkar överskatta sensitiviteten – att man av ren slump råkade få fler positiva svar än vad man kan förvänta sig. Statistiska verktyg – hypotestester och konfidensintervall – kan då användas för att få ett mått på osäkerheten i resultaten. I det här fallet så är studiens resultat bara tillräckliga för att säga att sensitiviteten är högre än 74 %. Det finns alltså inga statistiska belägg för att säga att sensitiviteten inte är 75 %, 80 % eller 85 %. Vilket tyvärr inte hindrar företaget som säljer testet från att påstå att sensitiviteten är betydligt högre än så.
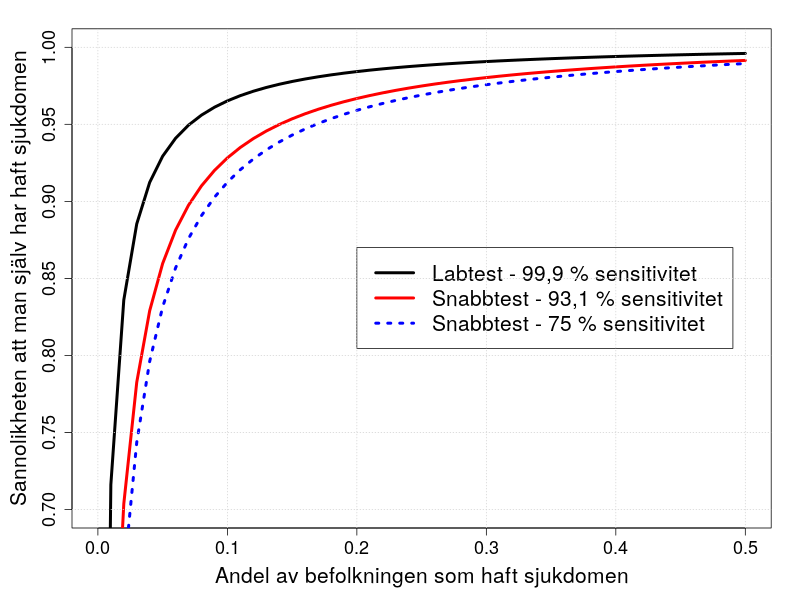
Vad betyder då resultaten man får från ett test? Svaret är att det beror på hur spridd sjukdomen är i befolkningen. Om ingen har haft sjukdomen så kommer exempelvis 100 % av de positiva resultaten att vara falska positiva, dvs. felaktiga positiva resultat. Ett labtest (som till skillnad från snabbtesten ger svar efter några dagar istället för efter några minuter) som används flitigt i Sverige uppges ha 99,6 % specificitet och 100 % sensitivitet (vilket knappast stämmer, så låt oss räkna med 99,9 % sensitivitet istället). Det innebär att om 1000 personer som inte haft sjukdomen testar sig så får 4 felaktigt ett positivt resultat, och om 1000 personer som har haft sjukdomen testar sig så får 1 felaktigt ett negativt resultat. Om man får ett positivt resultat och vet hur stor andel av befolkningen som har haft sjukdomen så kan man beräkna sannolikheten att man själv har haft den:
Om 7 % av befolkningen i en region har haft sjukdomen så kommer 95 % av de som får ett positivt resultat i ett labtest att ha haft sjukdomen, och 90 % av de som får ett positivt resultat i ett snabbtest. Om 20 % har haft sjukdomen blir motsvarande siffror 98,4 % och 96,7 %. Ett positivt resultat betyder alltså att det är troligt, men inte säkert, att man har haft sjukdomen. (Jag utgår då från att personer som haft och inte haft sjukdomen är lika benägna att testa sig.)
Inte krångligt nog? I fallet med covid-19 har det visat sig att många personer inte utvecklar antikroppar efter genomgången infektion, vilket gör resultaten av antikroppstesten ännu osäkrare. Fortfarande inte krångligt nog? I så fall kan det vara bra att ha i åtanke att antikroppar inte är samma sak som immunitet. Man kan ha antikroppar mot en sjukdom utan att vara (fullständigt) immun eller vara immun mot en sjukdom utan att ha antikroppar – de är bara ett av immunförsvarets verktyg mot virus. Ett negativt antikroppstest behöver därför inte nödvändigtvis betyda att man inte är immun, på samma sätt som att ett positivt resultat inte behöver betyda att man är immun eller inte kan sprida smittan till andra. Det finns fortfarande mycket vi inte vet om covid-19, och tills vidare finns inget annat att göra än att fortsätta följa Folkhälsomyndighetens rekommendationer – oavsett resultatet på ditt antikroppstest.
Jag erbjuder konsulttjänster, föredrag och utbildningar inom statistik – bland annat kring hur studier kan utvärderas. Kontakta mig för att få veta mer.
Coronaviruset har påverkat alla delar av samhället – inklusive sportens värld. I Sverige fick bland annat innebandyns slutspel ställas in. Serievinnarna IKSU (dam) och Falun (herr) tilldelades SM-guldet. Men hur sannolikt är det egentligen att de faktiskt hade vunnit slutspelet?
Jag har för Innebandymagazinets räkning tagit fram en modell som förutspår hur innebandyns slutspel borde ha slutat. Modellen bygger på matchresultat från de senaste två säsongerna och tar med olika parametrar hänsyn till hur bra de olika lagen är, dels på hemmaplan och dels på bortaplan. Med hjälp av modellen kunde jag sedan simulera slutspelet 1 000 000 gånger, för att se hur troliga olika resultat var.
Det finns mycket som påverkar resultatet i en match, och allt kan inte sammanfattas med siffror. Men däremot är det fullt möjligt att skapa modeller som säger hur sannolikt det är att olika lag vinner, samt vilka resultat som är mest troliga. Och det fungerar faktiskt – när vi testade min modell på förra årets herrslutspel så prickade den in rätt vinnare i samtliga kvarts- och semifinaler.
Innebandymagazinet kommer att släppa resultatet som modellen förutspår dag för dag fram till det som skulle ha varit finaldagen – den 25e april. För egen del ser jag fram emot att läsa vad spelare och tränare tycker och tänker om modellens resultat. De första artiklarna finns uppe redan nu:
I dagarna har det rapporterats om att Amazon lagt ner ett projekt där AI skulle användas för att sålla bland kandidater vid rekryteringar (IDG, Reuters). Anledningen är att AI-verktyget började diskriminera kvinnor och föredra manliga sökande.
Men hur kan en dator lära sig att diskriminera? Svaret finns i våra data.
Statistiker världen över har ägnat årtionden åt att fundera över hur man på bästa sätt ska samla in data för att kunna ge svar på de frågor man undrar över. Det finns många fallgropar när det gäller datainsamling. Två av dem är:
Obalanserat urval: om vi vill utföra en opinionsundersökning för att kunna göra en prognos för hur det svenska folket kommer att rösta i ett riksdagsval så duger det inte att exempelvis bara fråga personer i Danderyd, eftersom den gruppen helt enkelt inte är representativ för riket i stort. Om personerna i vårt datamaterial till största delen är från en liten del av samhället så kan våra data inte användas för att säga något om resten av samhället.
Felmärkta data: i studier där man ska lära en statistisk modell att till exempel diagnosticera en sjukdom så behöver alla patienter i datamaterialet att ”märkas” – antingen som att de har sjukdomen eller som att de inte har sjukdomen. Den märkningen utgör facit när modellen tränas att känna igen sjukdomen. Tyvärr är det vanligt att man helt enkelt inte har perfekta data. Diagnoser kan vara svåra att ställa och en del patienter får fel diagnos. Det kan finnas komplicerade gränsfall, ovanliga fall med andra symptom än de vanligaste och patienter som har symptomen men inte sjukdomen. Det gör att det ofta kan bli fel när patienterna som ingår i datamaterialet ska märkas – och de fel som sker vid märkningen lär sig den statistiska modellen att upprepa. Märkningen är modellens facit och den kan inte på egen hand upptäcka när det blivit fel.
Om man inte undviker fallgroparna så riskerar man att lura både sig själv och andra. Det gäller oavsett om man utför opinionsundersökningar eller utvecklar AI-verktyg för rekrytering.
I fallet med Amazons rekryterings-AI så finns det tecken på att de fallit i båda de ovan nämnda fallgroparna:
Obalanserat urval: Amazons datamaterial bestod av ansökningar som tidigare kommit in till företaget. En majoritet av dessa var från män. Det gör att det blir lättare för AI-systemet att känna igen anställningsbara män (eftersom det sett fler exempel på sådana). En fara med det här datamaterialet är också att systemet kan avfärda kandidater som inte liknar de som tidigare sökt sig till företaget – vilket gör att man riskerar att missa nya kompetenser.
Felmärkta data: om (så som ofta visats vara fallet) kvinnors kompetens nedvärderas i teknikbranschen medan mäns kompetens uppvärderas, så kommer det att finnas en felmärkning i datamaterialet. Kvinnor kommer felaktigt att av människor i genomsnitt bedömas som mindre kompetenta (och därmed inte märkas som anställningsbara) och män felaktigt att av människor i genomsnitt bedömas som mer kompetenta (och därmed märkas som anställningsbara). AI:n lära sig då att själv upprepa de felvärderingarna.
Att låta sökande bedömas av ett AI-verktyg är i teorin en jättebra idé. Datorn kan vara opartisk, rättvis och ge alla samma chans. Men om de data som används för att bygga upp verktyget inte är opartiska, rättvisa och ger alla samma chans blir effekten den motsatta. AI:n löser i så fall inte problemet med diskriminering – tvärtom cementerar den diskrimineringen.
Diskriminerande AI-system är på intet sätt något som är unikt för rekryteringsverktyg – ett annat exempel från i år är ansiktsigenkänningssystem som fungerar mycket bättre för vita män än för personer med annat kön eller annan hudfärg. Värt att understryka är att Amazon på eget bevåg lade ned projektet med AI-verktyg för rekrytering. Men hur många företag har gått och kommer gå vidare med AI-projekt utan att förstå vikten av att inte bygga in diskriminering i dem? Vad kommer de och vi att gå miste om när systemen fattar beslut på felaktiga grunder? Och hur kommer reaktionerna att bli när problemen med deras system avslöjas?
Jag erbjuder rådgivning kring datainsamling och hjälp med att bygga statistiska modeller och AI-system som undviker fallgroparna. Kontakta mig för att få veta mer.