AI inom medicin – en återvändsgränd?
Artificiell intelligens (AI) har under de senaste åren framställts som något som fullständigt kommer revolutionera sjukvården. Bland dem som leder hajpen märks Andrew Ng – Stanfordprofessor och ledande tänkare inom AI, med bakgrund på Google och Baidu:
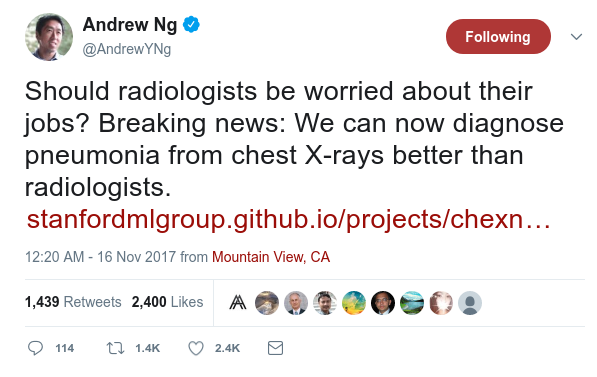
Stämmer det som Ng säger – har radiologer snart gjort sitt inom vården? Nej, knappast. En närmare titt i Ngs artikel visar att deras AI-modell utan alltför stor marginal lyckats identifiera lunginflammation bättre än fyra radiologer i en studie med drygt 400 röntgenplåtar. Det betyder förstås inte att den är bättre än alla radiologer eller ens radiologer i allmänhet – och dessutom har stora problem med studien påpekats: radiologerna och AI:n verkar inte ha bedömt samma bilder (vilket försvårar jämförelsen) och i datamaterialet finns tveksamma gränsdragningar mellan närliggande diagnoser.
I förra veckan kom ett uppföljningsarbete där samma AI-system användes för att bedöma radiologiska bilder från andra delar av kroppen. Resultatet var att AI:n var sämre än alla de tre radiologer som också gjorde bedömningar utifrån bilderna. Så borde radiologer oroa sig för att ersättas av maskiner? Inte än på ett tag (och dessutom har de förstås långt fler arbetsuppgifter än att titta på bilder).
Förutom att de mycket uppmärksammade radiologiresultaten visat sig vara överdrivna kom i veckan också nyheten att IBM Watson Health tvingats avskeda 50-70 % av sin personal. IBMs Watson har länge setts som ledande inom medicinsk AI och precisionsmedicin, men nu visar det sig alltså inte gå så bra som man hoppats.
Det här leder förstås till en fråga – är AI inom medicin överhajpat? På kort sikt är svaret nog ja. På längre sikt är det nog nej. Men AI inom medicin är svårt. Det finns flera anledningar till det:
- Dagens AI-system kräver stora mängder data för att nå bra resultat. För många sjukdomar finns det helt enkelt inte tillräckligt mycket data. Här finns förstås en stor potential för forskningsframsteg i de nordiska länderna, med våra stora nationella register.
- Förutom kvantitet krävs också kvalitet – om AI:n matas med dåliga data (exempelvis data innehållandes feldiagnosticerade patienter) blir resultaten genast sämre.
- Medicin är svårt och det är inte alltid lätt att på ett vettigt sätt dela in patienter i kategorier. Av den anledningen har man i flera AI-projekt valt att förenkla problemet genom att bara jämför fullt friska patienter med de allra svåraste fallen, vilket gör att man helt bortser från de mest svårbedömda (och därmed mest intressanta) fallen.
Framsteg inom medicin för AI kommer kräva nära samarbeten mellan AI-forskningen och vården – och inte minst en stor portion ärlighet. Det finns en enorm potential för användning av AI och maskininlärning inom vården, men vi måste också vara tydliga med de begränsningar som finns och inte överdriva hur långt vi redan har kommit.
- Jag finns tillgänglig för att ge föredrag om AI inom medicin, där jag presenterar några aktuella exempel på framgångsrika försök (jodå, de finns också!), överdriven hajp, säkerhetsrisker och problem när artificiell intelligens används för diagnostiska syften. Kontakta mig för mer information.
- Jag har sedan i vintras jobbat med det nederländska företaget Dairy Data Warehouse för att utveckla AI-drivna system inom veterinärmedicin. Mer om det projektet kommer på den här bloggen senare i år.