Coronaviruset visar utvecklingen inom AI
Uppdatering april 2020: Texten nedan skrevs i början av februari, innan det nya coronaviruset på allvar börjat spridas utanför Kina. Den handlar om hur AI kan användas för att upptäcka och bekämpa epidemier i ett tidigt skede snarare än när man fått stor samhällsspridning, och handlar därför inte om det allvarligare läge som många länder nu befinner sig i.
De senaste veckorna har nyhetsrapporteringen dominerats av spridningen av coronaviruset 2019-nCov. Ett ord som dyker upp gång på gång i de spaltmeter som skrivits om viruset är AI, och rapporteringen låter oss se vilka kliv utvecklingen inom AI tagit det senaste årtiondet. Det vi ser är imponerande.
Smittspridningen blev allmänt känd först i januari, även om den nu tros ha pågått sedan december. Redan då varnade det kanadensiska bolaget BlueDot sina kunder för att deras AI-system, som samlar in data från mängder av digitala källor, upptäckt spridningen av ett nytt virus i kinesiska Wuhan.
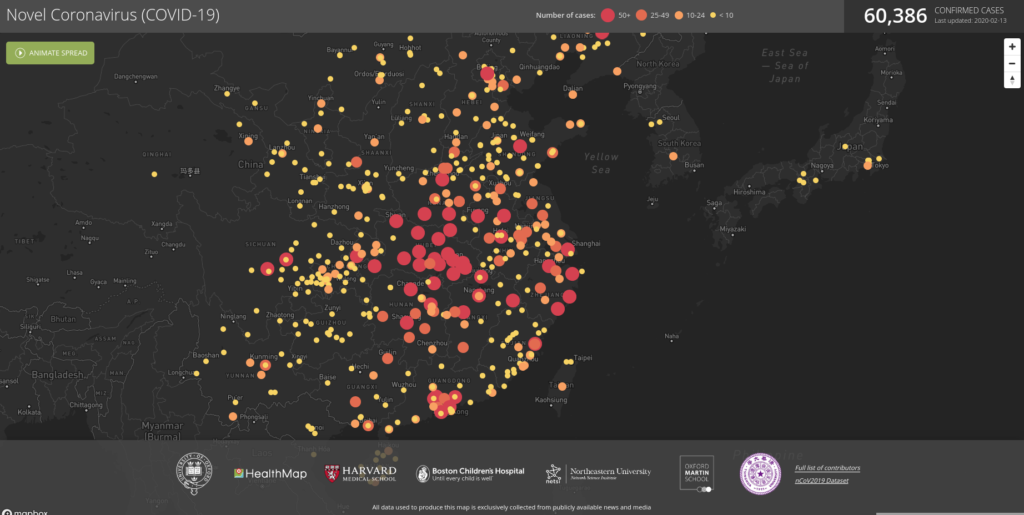
Men AI används inte bara för att kunna förutse hur epidemier sprider sig. Tvärtom så används AI för att bekämpa spridningen på flera olika sätt:
- AI-drivna botar har ringt upp Shanghaibor hörandes till riskgrupper och frågat dem om symptom. I en del fall har de rekommenderats karantän i hemmet, och botarna har då informerat myndigheterna om de misstänkta fallen. En bot kan genomföra 200 sådana samtal på 5 minuter, medan en människa hade behövt 2-3 timmar för att göra motsvarande jobb. Med AI kan myndigheterna snabbt nå ett stort antal människor under kriser.
- Autonoma robotar används för att desinficera slutna delar av sjukhus och servera mat till personer som satts i karantän. AI kan ta över farliga uppdrag från människor för att minska smittorisken.
- AI-system med infraröda sensorer mäter kroppstemperaturen på passagerare i kollektivtrafiken, för att upptäcka misstänka fall av smittan. Snabbare och effektivare än om varje kontroll genomförts av en spärrvakt.
- Stora kinesiska teknikbolag som Baidu och Alibaba har delat med sig av AI-algoritmer och datorkraft för att förstå virusets genetik, vilket snabbat upp processen flera gånger om.
- AI har använts för att ta fram kandidatmolekyler för läkemedel mot coronaviruset. Det gör att läkemedel förhoppningsvis kan tas fram på mycket kortare tid.
En titt på rapporteringen kring coronaviruset gör det tydligt att AI är inte längre science fiction, utan något som används överallt hela tiden. Vi stöter på AI varje dag i nätbutikers och strömningstjänsters rekommendationer, kartappar, skräppostfilter, kamerafilter och röstassistenter som Google Home och Siri. Samtidigt är den här en teknologi som fortfarande är ung, och som dras med problem som inbyggd diskriminering och bristande genomskinlighet. Att ha en grundläggande förståelse för AI blir allt viktigare för allt fler, dels för att förstå teknikens möjligheter och dels för att förstå dess begränsningar.
- Jag erbjuder konsulttjänster, föredrag och utbildningar inom AI, maskininlärning och statistik. Kontakta mig för att få veta mer.