Vad betyder resultatet av ett antikroppstest?
I takt med att allt fler har drabbats eller tror sig ha drabbats av covid-19 så växer intresset för antikroppstester, som man hoppas ska visa om man har haft sjukdomen eller inte. Olika aktörer erbjuder olika sorters antikroppstester, och alla möjliga siffror nämns i sammanhanget: 99,2 % säkerhet, 93 % sensitivitet, 99 % specificitet – och så vidare. Vad innebär det egentligen – och kan man lita på testens resultat?
När medicinska tester utvärderas finns två mått som man brukar utgå från:
- Sensitivitet: sannolikheten att testet ger ett positivt resultat för en person som har haft sjukdomen.
- Specificitet: sannolikheten att testet ger ett negativt resultat för en person som inte har haft sjukdomen.
Man önskar sig att både sensitivitet och specificitet ska vara så höga som möjligt. Låg sensitivitet gör att många som har haft sjukdomen felaktig får beskedet att de inte har haft det, och låg specificitet gör att många som inte har haft sjukdomen felaktig får beskedet att de har haft den – vilket i fallet med coronaviruset förstås kan vara väldigt problematiskt. Tyvärr finns det inga tester som har 100 % sensitivitet och specificitet – det finns alltid en risk för ett felaktigt svar – men det finns tester som åtminstone kommer nära.
För att ta reda på hur hög sensitiviteten och specificiteten hos olika tester är behöver man göra studier där man använder testen dels på personer som har haft sjukdomen och dels på personer som inte har haft sjukdomen, och kontrollerar om testet gav rätt svar. Ett problem är att det krävs ett stort antal personer för att få en bra uppfattning om hur hög sensitiviteten och specificiteten hos ett test faktiskt är.
Ett exempel på svårigheterna kan ses i en uppmärksammad svensk studie där en forskargrupp från Uppsala universitet utvärderade så kallade snabbtest för antikroppar mot covid-19. Bland de 29 personer som haft sjukdomen fick 27 ett positivt testresultat, vilket motsvarar en sensitivitet på 27/29 = 93,1 %. Problemet är att när så pass få patienter undersöks så finns en risk att man råkar överskatta sensitiviteten – att man av ren slump råkade få fler positiva svar än vad man kan förvänta sig. Statistiska verktyg – hypotestester och konfidensintervall – kan då användas för att få ett mått på osäkerheten i resultaten. I det här fallet så är studiens resultat bara tillräckliga för att säga att sensitiviteten är högre än 74 %. Det finns alltså inga statistiska belägg för att säga att sensitiviteten inte är 75 %, 80 % eller 85 %. Vilket tyvärr inte hindrar företaget som säljer testet från att påstå att sensitiviteten är betydligt högre än så.
Vad betyder då resultaten man får från ett test? Svaret är att det beror på hur spridd sjukdomen är i befolkningen. Om ingen har haft sjukdomen så kommer exempelvis 100 % av de positiva resultaten att vara falska positiva, dvs. felaktiga positiva resultat. Ett labtest (som till skillnad från snabbtesten ger svar efter några dagar istället för efter några minuter) som används flitigt i Sverige uppges ha 99,6 % specificitet och 100 % sensitivitet (vilket knappast stämmer, så låt oss räkna med 99,9 % sensitivitet istället). Det innebär att om 1000 personer som inte haft sjukdomen testar sig så får 4 felaktigt ett positivt resultat, och om 1000 personer som har haft sjukdomen testar sig så får 1 felaktigt ett negativt resultat. Om man får ett positivt resultat och vet hur stor andel av befolkningen som har haft sjukdomen så kan man beräkna sannolikheten att man själv har haft den:
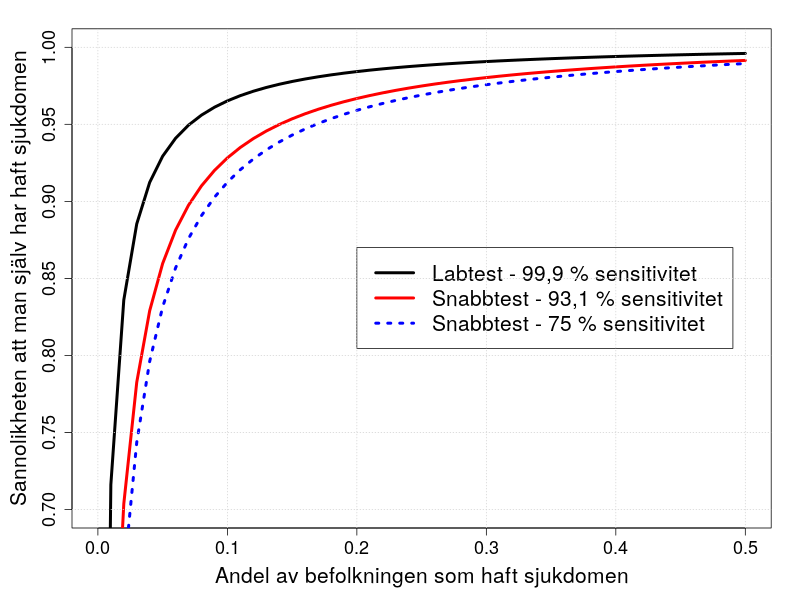
Om 7 % av befolkningen i en region har haft sjukdomen så kommer 95 % av de som får ett positivt resultat i ett labtest att ha haft sjukdomen, och 90 % av de som får ett positivt resultat i ett snabbtest. Om 20 % har haft sjukdomen blir motsvarande siffror 98,4 % och 96,7 %. Ett positivt resultat betyder alltså att det är troligt, men inte säkert, att man har haft sjukdomen. (Jag utgår då från att personer som haft och inte haft sjukdomen är lika benägna att testa sig.)
Inte krångligt nog? I fallet med covid-19 har det visat sig att många personer inte utvecklar antikroppar efter genomgången infektion, vilket gör resultaten av antikroppstesten ännu osäkrare. Fortfarande inte krångligt nog? I så fall kan det vara bra att ha i åtanke att antikroppar inte är samma sak som immunitet. Man kan ha antikroppar mot en sjukdom utan att vara (fullständigt) immun eller vara immun mot en sjukdom utan att ha antikroppar – de är bara ett av immunförsvarets verktyg mot virus. Ett negativt antikroppstest behöver därför inte nödvändigtvis betyda att man inte är immun, på samma sätt som att ett positivt resultat inte behöver betyda att man är immun eller inte kan sprida smittan till andra. Det finns fortfarande mycket vi inte vet om covid-19, och tills vidare finns inget annat att göra än att fortsätta följa Folkhälsomyndighetens rekommendationer – oavsett resultatet på ditt antikroppstest.
- Jag erbjuder konsulttjänster, föredrag och utbildningar inom statistik – bland annat kring hur studier kan utvärderas. Kontakta mig för att få veta mer.



